Now that msm drm/kms kernel driver is merged upstream, I've spent the last few weeks on a bit of a debugging / fixing spree. (Yes, an odd way to start a post about performance/profiling.) I added proper support for mipmaps/cubemaps/etc (multi-slice resources), killed a few gpu lockup bugs, installed a bunch of games and went looking for and fixing rendering issues. I've put together a status table on the freedreno wiki.
In the process, I noticed some games, such as supertuxkart, which had low fps, also also had unusually low gpu utilization (30-50%). Now, a new graphics driver stack will always have lots of room for optimization (which is certainly true of freedreno). The key is to know which optimization to work on first. It does no good to make the shader compiler generate 2x faster shaders (which I think is currently possible) if that is just going to take you from 30-50% utilization to 15-25% utilization at roughly the same fps. So before we get to the fun optimizations, we need to take care of any of the cpu side bottlenecks in the driver.
Now the linux perf tool is pretty nice just for identifying purely cpu bottlenecks. In fact it showed me pretty quickly that the upstream IOMMU framework struggles with gpu type workloads. Mapping/unmapping individual pages is not really the way to do it. On the downstream msm-3.4 based android kernel, we have iommu_map_range() and iommu_unmap_range()[1]... using these instead is worth 2-3 fps in xonotic, and probably more in supertuxkart, but we'll come back to that.
But perf tool does not really help much with gpu or cpu/gpu interactions, at least not by itself. So, first I added some trace points in the kernel drm/kms driver.. in particular, I put tracepoints:
With that, I fired up supertuxkart again (in demo mode so it will drive itself), and then perf timechart record for a couple seconds to capture a short trace:
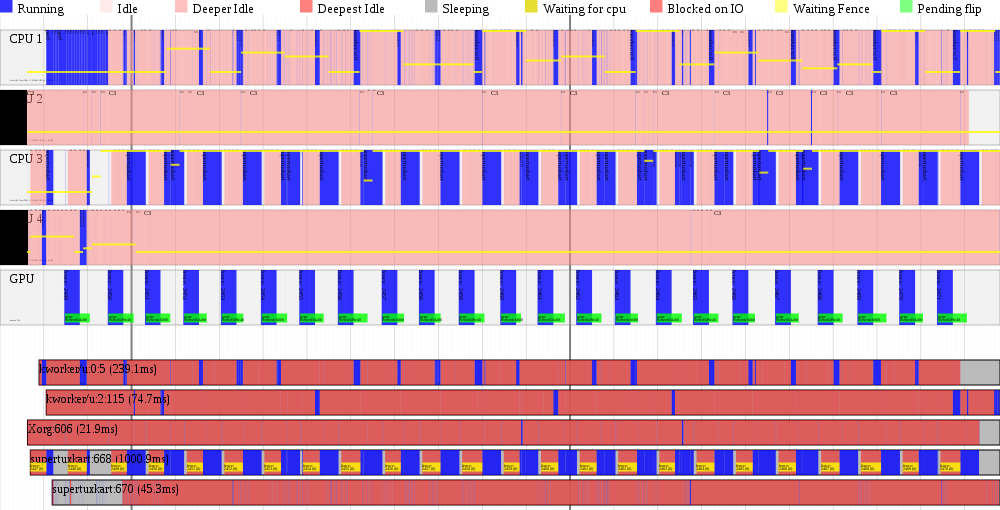
You can see above, there is a new bar at the top, below the cpu bars, for the gpu, showing when the gpu is active. And a green overlay bar on the gpu showing where pageflip has been requested (typically right after rendering submitted), and when pageflip completes (next vblank after rendering completes. And below, in the per-process bars, a yellow overlay marker when the process is pending on a fence (waiting for some gpu rendering to complete).
And immediately we can see see that that the bottleneck is a fence that supertuxkart is stalling on before it is able to submit rendering for the next frame. After a little bit of poking, I realized that I should implement support for PIPE_TRANSFER_DISCARD_WHOLE_RESOURCE in the freedreno gallium driver. If this usage bit is set, it is a hint to the gallium driver that the previous buffer contents do not need to be preserved after the upload. So in cases that the backing gem buffer object (bo) is still busy (referenced by previous rendering which is not yet complete), it is better to just delete the bo and create a new one, rather than stalling the cpu. The drm driver holds a ref for bo's that are associated to gpu rendering which has not yet completed, so the pages for the old bo don't go away until the gpu is finished with them.
With this change, things have improved, but there is still a bottleneck:
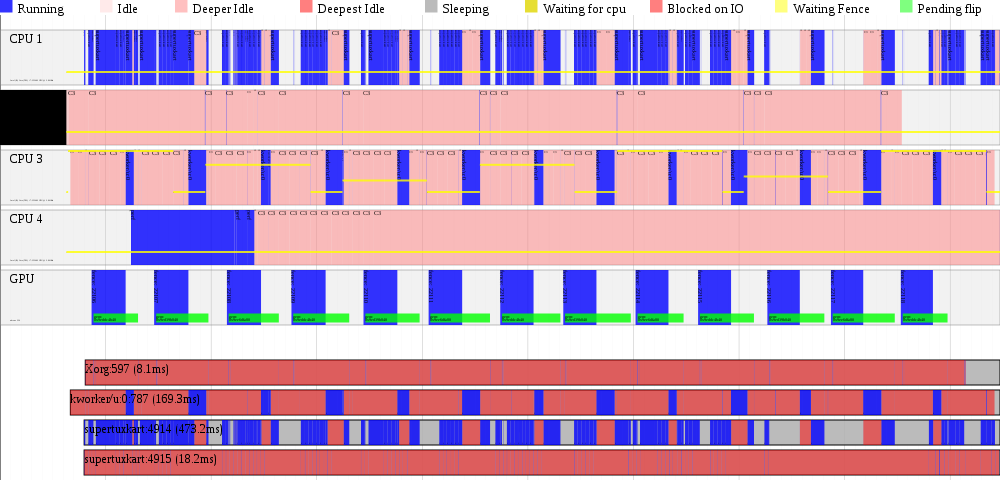
(note that the timescale differs between these three timecharts, since the capture duration differed)
Oddly we see a lot of activity on kworker (workqueue worker thread in the kernel). This is mainly retire_worker, in particular releasing the reference that the driver holds to bo's for rendering which is now completed. After a bit more digging, it turns out that supertuxkart is creating on the order of 150-200 transient buffers per frame. Unref'ing these, unmapping from IOMMU and cpu, and deleting backing pages for that many buffers takes some time. Even with some optimization in the kernel, there is still going to be a lot of overhead in the associated vma setup/teardown (since many of these buffers are used for vertex/attribute upload, and will need to be mmap'd), zeroing out pages before the next allocation, etc.
So borrowing an idea from i915, I implemented a bo cache in userspace, in libdrm_freedreno. On new allocations, we round up to the next bucket size, and if there is a unused buffer in the bucket cache which is not still busy, we take that buffer instead of allocating a new one. (If I add a BO_FOR_RENDERING flag, like i915, I could take a still-busy gem bo for cases where I know cpu access will not be needed... by the time the gpu starts writing to the buffer, it will be no longer busy.)
With this, things look much better:
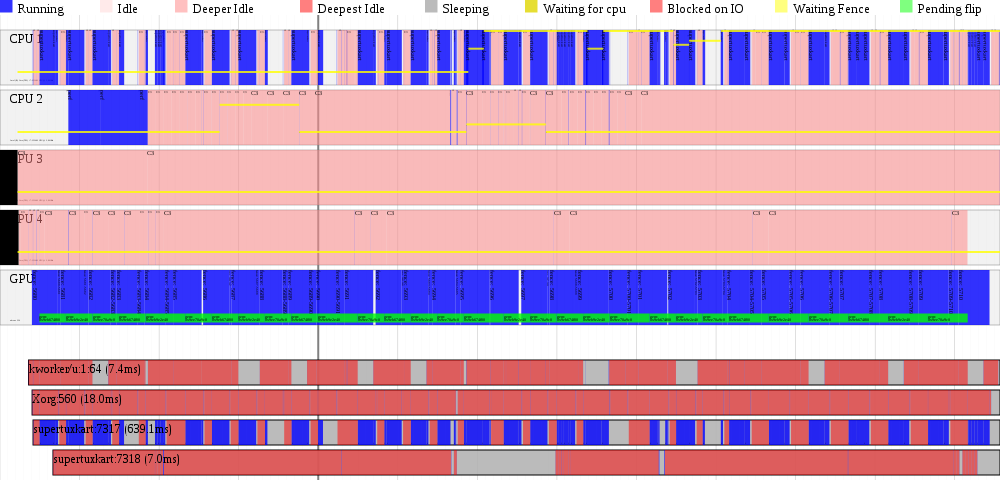
As you can see, the gpu is nearly continuously occupied. And a nice benefit is a drop in cpu utilization. To do this properly, I need to add a MADVISE style ioctl in msm drm/kms driver, so userspace can advise the kernel that it is keeping a bo around in a cache, and that the kernel is free to free the backing pages under memory pressure, tear down the cpu mapping, etc. This will prevent the wrath of the OOM killer :-)
So now with the bottlenecks in the driver worked out, future work to make the gpu render faster (ie, hw binning pass, shader compiler optimizations, etc) will actually bring a meaningful benefit.
Notes:
[1] just fwiw, the ideal IOMMU API would give me a way to make multiple map/unmap updates without tlb/etc flush. This should be even better than the map/unmap_range variants. I know when I'm submitting rendering jobs which reference the buffers to the GPU, so I have good points for a batch IOMMU update flush.
In the process, I noticed some games, such as supertuxkart, which had low fps, also also had unusually low gpu utilization (30-50%). Now, a new graphics driver stack will always have lots of room for optimization (which is certainly true of freedreno). The key is to know which optimization to work on first. It does no good to make the shader compiler generate 2x faster shaders (which I think is currently possible) if that is just going to take you from 30-50% utilization to 15-25% utilization at roughly the same fps. So before we get to the fun optimizations, we need to take care of any of the cpu side bottlenecks in the driver.
Now the linux perf tool is pretty nice just for identifying purely cpu bottlenecks. In fact it showed me pretty quickly that the upstream IOMMU framework struggles with gpu type workloads. Mapping/unmapping individual pages is not really the way to do it. On the downstream msm-3.4 based android kernel, we have iommu_map_range() and iommu_unmap_range()[1]... using these instead is worth 2-3 fps in xonotic, and probably more in supertuxkart, but we'll come back to that.
But perf tool does not really help much with gpu or cpu/gpu interactions, at least not by itself. So, first I added some trace points in the kernel drm/kms driver.. in particular, I put tracepoints:
- tracing the fence # when work is submitted to the gpu, and when we get the completion interrupt.
- tracing the fence # when cpu waits on a fence and when it finishes waiting
- and when pageflip is requested and when it completes (after rendering completes and after vsync)
With that, I fired up supertuxkart again (in demo mode so it will drive itself), and then perf timechart record for a couple seconds to capture a short trace:

You can see above, there is a new bar at the top, below the cpu bars, for the gpu, showing when the gpu is active. And a green overlay bar on the gpu showing where pageflip has been requested (typically right after rendering submitted), and when pageflip completes (next vblank after rendering completes. And below, in the per-process bars, a yellow overlay marker when the process is pending on a fence (waiting for some gpu rendering to complete).
And immediately we can see see that that the bottleneck is a fence that supertuxkart is stalling on before it is able to submit rendering for the next frame. After a little bit of poking, I realized that I should implement support for PIPE_TRANSFER_DISCARD_WHOLE_RESOURCE in the freedreno gallium driver. If this usage bit is set, it is a hint to the gallium driver that the previous buffer contents do not need to be preserved after the upload. So in cases that the backing gem buffer object (bo) is still busy (referenced by previous rendering which is not yet complete), it is better to just delete the bo and create a new one, rather than stalling the cpu. The drm driver holds a ref for bo's that are associated to gpu rendering which has not yet completed, so the pages for the old bo don't go away until the gpu is finished with them.
With this change, things have improved, but there is still a bottleneck:

(note that the timescale differs between these three timecharts, since the capture duration differed)
Oddly we see a lot of activity on kworker (workqueue worker thread in the kernel). This is mainly retire_worker, in particular releasing the reference that the driver holds to bo's for rendering which is now completed. After a bit more digging, it turns out that supertuxkart is creating on the order of 150-200 transient buffers per frame. Unref'ing these, unmapping from IOMMU and cpu, and deleting backing pages for that many buffers takes some time. Even with some optimization in the kernel, there is still going to be a lot of overhead in the associated vma setup/teardown (since many of these buffers are used for vertex/attribute upload, and will need to be mmap'd), zeroing out pages before the next allocation, etc.
So borrowing an idea from i915, I implemented a bo cache in userspace, in libdrm_freedreno. On new allocations, we round up to the next bucket size, and if there is a unused buffer in the bucket cache which is not still busy, we take that buffer instead of allocating a new one. (If I add a BO_FOR_RENDERING flag, like i915, I could take a still-busy gem bo for cases where I know cpu access will not be needed... by the time the gpu starts writing to the buffer, it will be no longer busy.)
With this, things look much better:

As you can see, the gpu is nearly continuously occupied. And a nice benefit is a drop in cpu utilization. To do this properly, I need to add a MADVISE style ioctl in msm drm/kms driver, so userspace can advise the kernel that it is keeping a bo around in a cache, and that the kernel is free to free the backing pages under memory pressure, tear down the cpu mapping, etc. This will prevent the wrath of the OOM killer :-)
So now with the bottlenecks in the driver worked out, future work to make the gpu render faster (ie, hw binning pass, shader compiler optimizations, etc) will actually bring a meaningful benefit.
Notes:
[1] just fwiw, the ideal IOMMU API would give me a way to make multiple map/unmap updates without tlb/etc flush. This should be even better than the map/unmap_range variants. I know when I'm submitting rendering jobs which reference the buffers to the GPU, so I have good points for a batch IOMMU update flush.

Hi,
ReplyDeleteI just want to thank you for your work on free gpu drivers for embedded systems. Please keep up the good work :)
Your blog articles are quite nice to read.
-- Sebastian
thanks :-)
DeleteYour target devices are probably more memory constrained than desktops, but we lived for a *long* time without madvise (just freeing things after a second sitting idle). madvise is totally necessary long term, though.
ReplyDeletetime to give up Ubuntu Touch for awhile and go back to the "Rob Clark" way of things. =) Thanks Rob! I have 3 TP's now.. =)
ReplyDeleteHey Rob, this looks awesome! Is it possible to build freedreno as a drop-in replacement for Android or an AOSP-based OS? Or are the drivers tied to X11?
ReplyDeletexf86-video-freedreno would obviously not be needed for android. And there isn't anything android (or x11 or wayland) specific in freedreno gallium driver. Mesa does seem to have support for android.. probably missing are the Android.mk build file stuff, but I don't really know much about how to build android, so someone else would need to add that
Delete